
by Peter Bauer Friday, October 14, 2016
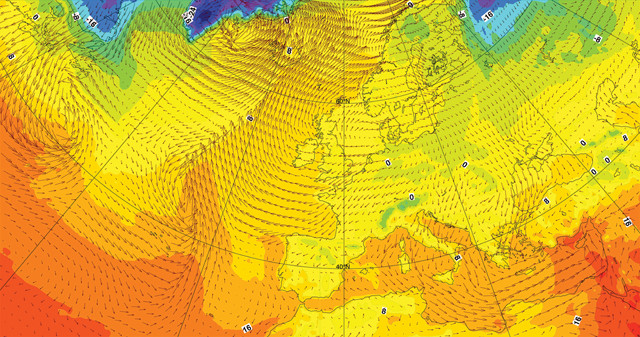
The European Center for Medium-Range Weather Forecasts (ECMWF) produces operational analyses and predictions that describe the range of possible scenarios and their likelihood of occurrence, covering time frames ranging from medium range to monthly to seasonal. The arrows on the map correspond to wind speed and direction. Credit: ECMWF..
When people look to their phones, computers or TVs for weather forecasts, they want the forecasts to be accurate and timely. What goes into creating a forecast is rarely a concern, so long as it tells them whether to carry an umbrella or jacket that day, when to evacuate because a hurricane is coming, or when to prepare for a heat wave. It’s the job of the weather scientists, armed with computer models and an array of weather-observing instruments, to make accurate predictions. Yet, even with advancing technology, improving forecasts is challenging.
Weather forecasts have improved significantly since the first numerical, physics-based computer models were implemented in the 1950s. This improvement is on display every day as we observe key weather variables with both ground-based instrument networks and satellites, and compare these variables with current forecasts. The overall improvement in weather forecasting since the mid-20th century has amounted to about a day per decade; in other words, today’s six-day forecast is about as accurate as a five-day forecast 10 years ago.
The trend of increasing accuracy, or skill, of current forecasts holds for both large-scale weather patterns, like frontal systems (think East Coast snow storms), and also for smaller-scale features like precipitation at the surface. In terms of severe weather warnings, a one-day margin translates to enormous savings of lives and property. A one-day gain of skill is therefore invaluable and well worth the investment needed to achieve it.
But what is needed in the future to allow us to continue improving our forecasts?
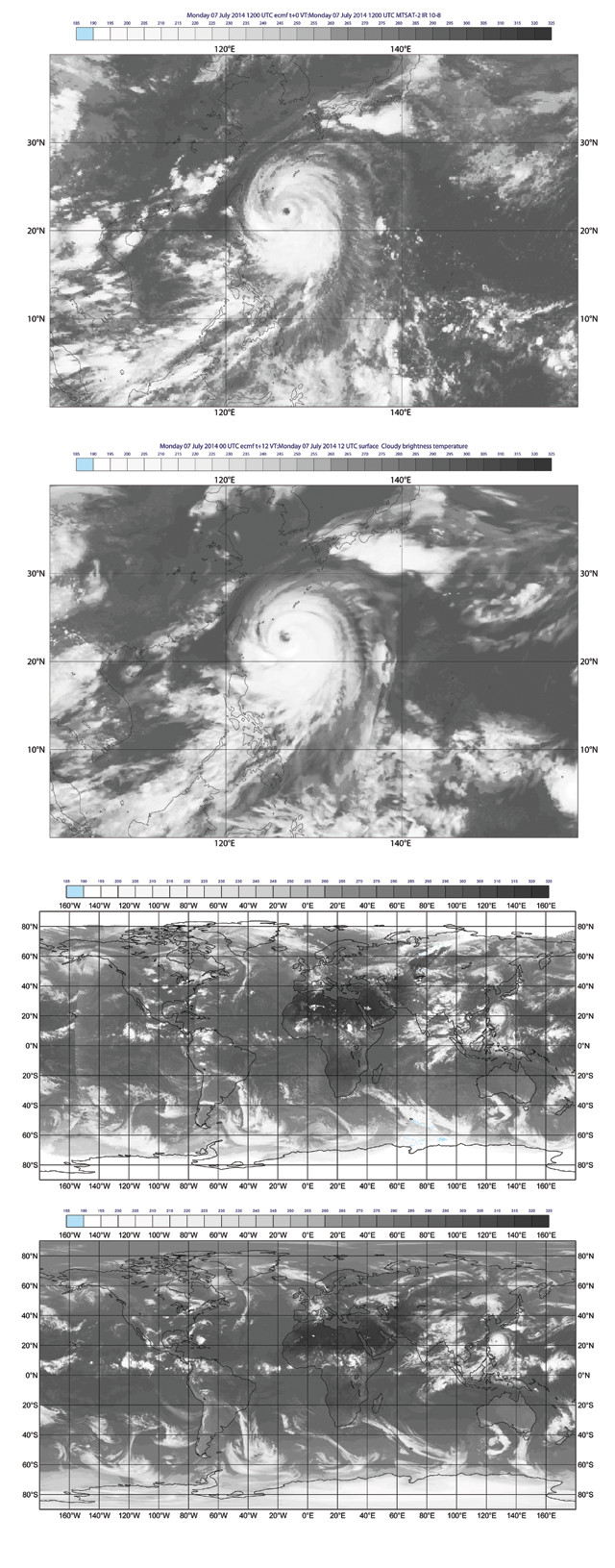
From top to bottom: Actual satellite observations from the Japanese satellite MTSAT-2 of Tropical Cyclone Neoguri in July 2014. Simulated satellite observations relying on ECMWF's model outputs for the same point in time. A global satellite view combining observations from five different satellites. The ECMWF's simulated global satellite observations. Although there are noticeable differences, the models represent reality rather well. Credit: all: Cristina Lupu, ECMWF.
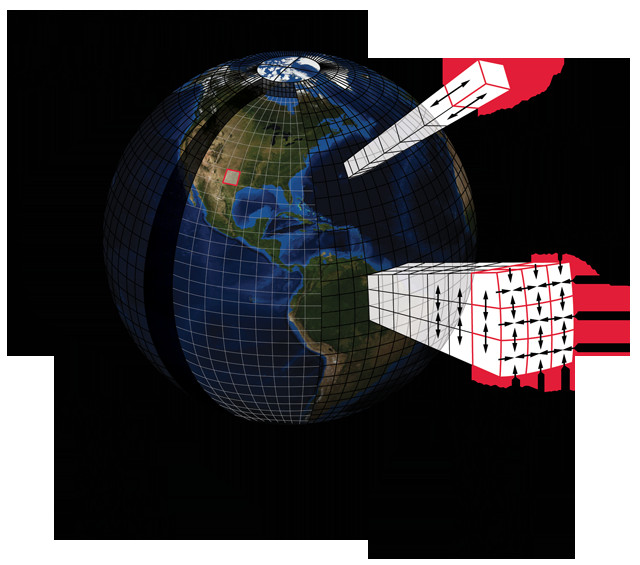
This graphic illustrates the huge number of variables that go into a weather forecast. Using 10-kilometer spatial resolution globally, or about 5 million grid points, with 100 vertical levels and 10 physical prognostic variables (like temperature, humidity and wind) in the equations, produces a model with a dimension of 5 billion (5 million grid points x 100 vertical levels x 10 variables). Credit: K. Cantner, AGI.
Weather forecasting is fundamentally a product of massive computer simulations. Atmospheric motions, and all the processes that go with them, are simulated in three spatial dimensions over time. The simulations are based on the laws of physics that define, for example, how a fluid — in this case, air — moves as it is either heated by absorbing sunlight or cooled by emitting infrared radiation, as well as how such processes operate over a rotating, spherical surface. Heating and cooling are heterogeneous in space and time because land and sea have distinct heat capacities and dynamics. Clouds and aerosols in the atmosphere also change heating patterns through absorption and reflection, and cloud formation itself produces heating while evaporation causes cooling. All of these processes interact on a wide range of scales, and it takes many laws and equations to describe the physics of the Earth system so that weather-related phenomena can be predicted.
With all of the necessary equations in hand, the next step is to apply the equations in a simulation, which means developing a computer program. Just like complex computer games featuring three-dimensional animations of landscapes, a weather simulation must be as realistic as possible, especially relative to its physical accuracy.
Translating physical laws into a simulation involves formulating equations such that calculations can be performed for discrete points in space, discrete layers in the atmosphere, and for advancing time — a process we call discretization. The distance between discrete points considered in models, referred to as the spatial resolution, is a key part of creating accurate representations of atmospheric physics and translates into the size of features that a model can resolve. For example, if a model’s spatial resolution is 10 or 50 kilometers, it will not resolve small and medium-sized storms, lakes, or types of land cover. But if it’s 1 kilometer, then it not only resolves storms, lakes and land cover, but it also resolves most clouds and will better represent the impact these clouds have on heating or cooling the atmosphere and on precipitation generation.
Computer codes for weather forecasting contain millions of lines. Scientists are continually revising these codes to improve their realism. At the European Center for Medium-Range Weather Forecasts (ECMWF) in Reading, England, where I work, a new version of the forecasting system is implemented about twice per year. This involves integrating improvements in many different components, such as adding new types of weather observations, modifying details of the model physics and/or simply improving the computer code so that it runs faster on modern computers. Most operational forecast centers implemented their first supercomputing systems in the 1970s. These systems have greatly evolved since then, both from scientific advances and from vast improvements in computing power, allowing us to add much more physical detail to simulations.
With a model simulation code implemented, the process of forecasting starts with the initial conditions: the best possible description of the current state of the atmosphere, land surface and oceans. This can only be done by observing as much of the system as possible, by transmitting observation data to the forecast center as fast as possible, and by converting this information into a form that the forecast model can use as fast as possible. Speed is of the essence because the longer this step takes, the more out of date the initial state will be, and thus the more out of date the forecast will be.

This still image from an animated map of global weather conditions shows the winds produced during Tropical Cyclone Neoguri, which struck Japan in July 2014. Forecast models and actual satellite observations from the same time period can be seen on the opposite page. Credit: Cameron Beccario, https://earth.nullschool.net/.
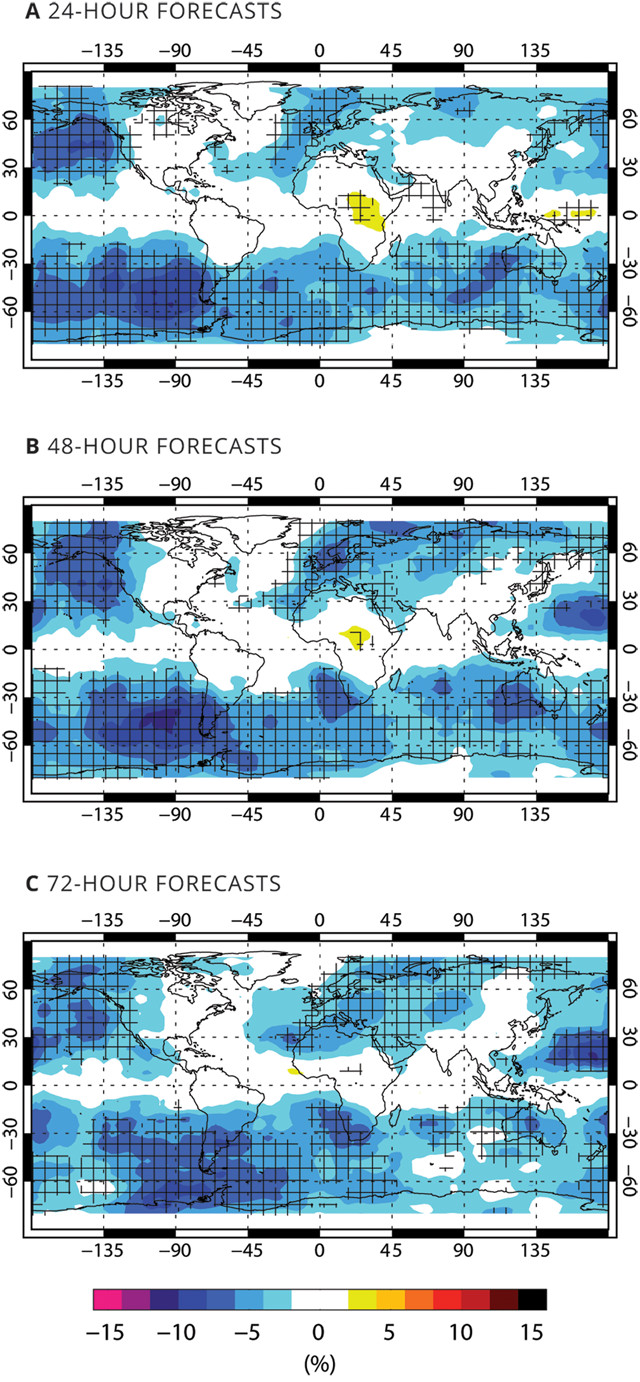
Observations from multiple vantage points can reduce error, as shown in these figures based on six months of experimental data. Blue areas in these forecast maps show how observations of moisture, clouds and precipitation — made using seven different satellites — reduced forecast errors. Cross-hatching indicates statistical significance at the 95-percent confidence level. Credit: all: A. Geer, ECMWF.
Fortunately, national governments, space agencies and international coordination organizations like the World Meteorological Organization have invested large sums of money to install and maintain observing networks on the ground and to launch fleets of satellites into space to provide these observations, which are freely available across the planet. The bulk of these data is available within hours — a major achievement in itself, as many terabytes of data are collected and distributed across the planet daily. (The meteorological community is one of the best-organized science communities in this respect.)
Once the observations are available and transmitted to a forecast center, they are used — together with the forecast model — to produce the initial state simulation. In terms of computing, establishing the initial conditions is as much computational effort as the forecast itself.
The final step of building a forecast is running dozens of forecast simulations to generate an estimate of forecast uncertainty, a process we call ensemble forecasting. A single forecast provides only one possible realization of future weather. But there is always uncertainty because both models and estimated initial conditions are imperfect. Combining multiple potential realizations through ensemble forecasting, however, offers crucial information about the uncertainty of the average realization.
In terms of computational cost, the more ensemble realizations, also called ensemble members, are run, the higher the cost. At ECMWF, we typically run 50 members; thus, the ensemble is 50 times more expensive to run and produces 50 times as much data as a single forecast at the same resolution.
Given the massive dimension of scientific weather forecasting, it is obvious that powerful computers are required; and to improve forecasts, even more powerful computers will likely be necessary. So, how powerful are they today and how powerful will they need to be? Some brief back-of-the-envelope calculations might help us consider these questions. The primary goal of numerical weather prediction is to deliver accurate forecasts on time. Today, at ECMWF, we produce a single 10-day forecast in one hour. Determining initial conditions, running ensemble forecasts, performing post-processing steps, and disseminating forecasts add time, but for simplicity let’s focus on the execution of a single high-resolution 10-day forecast.
At 10-kilometer spatial resolution globally (which requires 5 million grid points to cover the whole planet), with 100 vertical levels (think of these as building stories, each representing a different level in the atmosphere), and with about 10 physical prognostic variables considered in the equations (like temperature, humidity and wind), we obtain a global model dimension of 5 billion. We in the meteorology community hope, over time, to increase resolution to about 1 kilometer; to split the atmosphere into 200 vertical levels; to factor in chemical processes; and also to include complex land surface, ocean, sea-ice cover and even vegetation models requiring perhaps 100 prognostic variables. This would boost a given model’s dimension by a factor of 2,000 relative to what it is today. This increase is per time step, and if one enhances resolution and complexity, more time steps will be needed to complete a 10-day forecast.
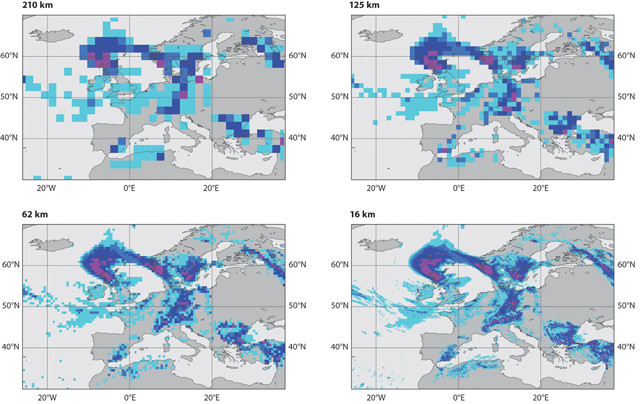
These images show the increasing resolution of forecasts, from 210 kilometers down to 16 kilometers, that has been achieved during the 40 years ECMWF has been in existence. Today, the resolution is 9 kilometers, and a seven-day forecast is as accurate as a three-day forecast was four decades ago. Credit: all: ECMWF.
Today, at ECMWF, to complete a 10-day forecast in one hour, the model runs on a portion of a supercomputing system composed of about 10,000 processors. With the improvements expected in the next decade, we would need 20 million processors to do the same job, if everything scales perfectly. This would require a computer in excess of 100 times more powerful than any ECMWF has on its premises today.
Clearly, using current technology to scale up forecast simulations to achieve the desired improvements is not feasible. Computer systems using 20 million processors aren’t realistic, for example. So, we have to figure out how to make the computations more efficient. Many countries are currently investing substantially in research aimed at identifying new scientific methods, new mathematical algorithms, new programming models and new computing hardware to make computations of the required size affordable. This challenge goes beyond weather and climate prediction; it’s shared by many other fields within science and engineering and is a truly global problem that will need much additional intellectual and financial investment over the next 10 years.

The Titan supercomputer at Oak Ridge National Laboratory in Tennessee is one of the fastest in the world. Even faster and more powerful supercomputers will be required to improve weather forecasts in the future. Credit: Oak Ridge National Laboratory.
Model resolution is among the favorite ways to improve forecasts. But translating improved resolution into forecast skill is not as easy as it seems.
Model errors become smaller when a model’s spatial resolution increases (resolving finer scales) and when surface characteristics — such as mountains, oceans, snow, and land and sea-ice cover — can be described in more detail. Enhanced resolution also reduces errors in the description of physical processes that usually occur on scales smaller than those that can be resolved by a model, such as convective cloud systems that can produce severe storms.
Models have specific mean errors that change with height in the atmosphere and also spatially, changing with forecast time. The root causes of these errors are not well known and mostly relate to the use of simplified descriptions of physical processes. When running an entire model, errors in separate parts of the model become additive and produce convoluted errors that are very difficult to disentangle. So, when model resolution is changed, the characteristics of the errors generated change as well, which, despite the intended benefits, can easily produce worse forecasts.
Another effect of increasing model resolution is that a model becomes more “active.” A model’s activity is the level of variability it produces. Less active could mean that temperatures vary only on very large scales, and rather slowly, along a forecast compared to reality. Enhanced activity follows from the addition of small-scale features resolved in a model, which is what we expect with increased resolution. But enhanced activity can also be an artifact produced by instabilities in the way the physical equations are cast in the model. Instabilities can be filtered — just like when you use a color filter for your camera that only allows certain wavelengths to pass. Therefore, once model resolution is changed, these protective filtering mechanisms need to be adjusted. But the fact that filtering is applied also means the benefit of increasing the resolution may be partly lost because some fine-scale features may be filtered out as well.
Beyond improving resolution, adding complexity in models to produce forecast improvements is also a tough task, one that requires addressing fundamental science questions. Of key importance is aerosols, tiny particles that typically include dust, sand, volcanic ash, soot and sea-salt spray, as well as pollution. Aerosols affect atmospheric heating by reflecting solar radiation; they can affect cloud formation; and they can be involved in chemical processes like the reactions that produce chemicals involved in the destruction of ozone. Depending on the origins of the aerosols and the environment, these effects can be significant. To include them in models means that scientists must understand the types and quantities of aerosols present, where they are coming from, and how their physical and chemical interactions actually work.
Neglecting aerosols has produced systematic model errors in previous work. But including aerosols in models requires having accurate global observations of aerosol abundances and types so that this information — like temperature, humidity and other parameters — can be input at the start of the forecast simulation. Unfortunately, these detailed observations do not exist and our physical aerosol models are still pretty basic. It is therefore not obvious that adding aerosol effects — given today’s capabilities — will really improve current weather forecasts. Scientists have a lot of work to do in this area.
Another issue is atmosphere-ocean interactions. Atmospheric and ocean models each have average, or mean, errors, and problems can arise at the interface between the two. The atmosphere and oceans interact by exchanging energy. This energy is associated with momentum, heat and radiation. Mean errors in atmospheric and ocean models can collide at the interface and can produce imbalance. This can cause a chain reaction in which other processes in the atmosphere and the oceans compensate for imbalances. Imagine the ocean model producing sea-surface temperatures that are always too warm. This would produce, in the model, excessive heating at the bottom of the atmosphere, which in turn would produce too much convection and rain, and too much freshwater flux back into the ocean. These types of issues are particularly serious in climate models that must accurately represent small variations, or anomalies, over long timescales to, for example, distinguish between natural variability and human influence. We have a lot of work to do in this area as well.
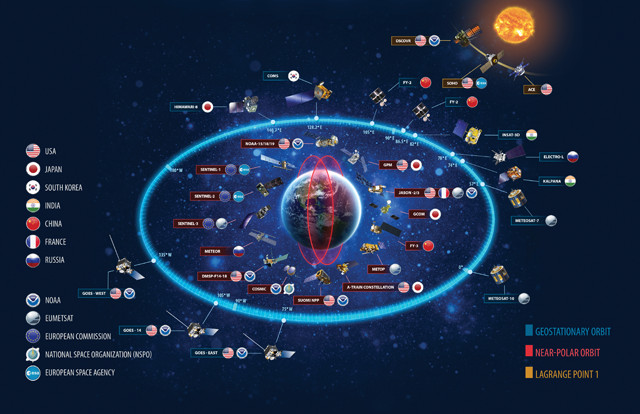
The many satellites of the space-based portion of the World Meteorological Organization's Global Observing System, plus additional space weather and environmental satellites, as of October 2015. Credit: NOAA.
More reliable forecasts will require better model ensembles, which means ensembles with more members. More ensemble members are needed when a model becomes more complex and has higher resolution because it will take more individual forecasts to reproduce the full range of realistic forecast scenarios adequately. Individual members can be run in parallel, so more powerful computers will clearly help. But larger ensembles obviously produce a lot more data than smaller ones or single forecasts, and managing these data, and producing ensemble forecast-specific user products, is another huge task on its own. An example is an error bar for a single forecast. A more sophisticated ensemble forecast product would estimate the probability of an extreme event occurring, say the probability of wind gusts exceeding 100 kilometers per hour, or the probability that a tropical cyclone would strike a certain piece of coastline. Having better ensembles will take serious investment in data infrastructure, as well as in the scientists who do these types of calculations.

Observations from satellites, like CloudSat and CALIPSO or the EarthCARE mission (launching in 2018), provide information on the vertical structure of clouds, including how much water and ice they contain, and how they affect the distribution of solar energy in the atmosphere — which helps researchers better understand atmospheric circulation models and weather patterns. Credit: NASA.
There are a number of facets to improving numerical weather forecasting and, thus, the forecasts you get on your phone or computer, or from your local weather station. Higher-resolution global observation data will allow us to include better descriptions of the initial conditions that serve as the starting points for forecast models. We’ll need more realistic and computationally efficient models, which will come from fundamentally changing the way we design computer models to compute forecasts. We’ll need powerful computers to be sure — but, even more, we’ll need many well-trained scientists focused on the task ahead.
The issue of scalability is also always present. If a model is perfectly scalable, it means that if it were run on twice as many processors, it would take half the time to complete, or a fourth of the time if it were run on four times the number of processors. Likewise, a forecast model that increases resolution by doubling the number of grid points, or that doubles complexity, should be completed in the same time if run on twice as many processors. It doesn’t quite work this way, however. Many forecast model calculations for millions of grid points are distributed onto the available processors so that calculations can be done in parallel. This only works if calculations are independent from each other.
Imagine a calculation that, at some point, must sum the values of a variable over all grid points and levels in the atmosphere. The calculation needs to collect data from all the processors involved, perform the summation and then redistribute the result so that the parallel calculations can be continued. This is an example of global communication. But communicating data across thousands of processors versus millions of processors has very different impacts on computing performance: The bigger the communicated data volumes become — due to increased model resolution, for example — the worse performance gets. Communication kills scalability, and, therefore, the smarter way to proceed is to reduce data exchange between processors by using different numerical methods or new ways of coding that don’t require as much communication, both of which are nontrivial.

ECMWF brings together meteorologists from around the world to facilitate collaboration and to train them on using ECMWF's products. Credit: ECMWF.
Forecast models are not based on plug-and-play systems in which parts can be easily taken out and replaced, or in which enhancing resolution inevitably results in better forecasts. Every change in a model requires thorough scientific rethinking and retesting, and the more complex models become, the harder it becomes to produce improvement. This rethinking and testing calls for very skilled scientists!
The challenge of the next decade is to bring applied science and computing science closer together and to use available resources in clever ways. The old paradigm of physical scientists creating code that is then handed over to a programmer to tweak, optimize and implement is history. The new term “co-design” applies: It means that physical scientists, computer scientists and even computer hardware providers have to work very closely together to produce the optimal combination of physical science, numerical methods, hardware and software to accurately model the science and to enhance model execution on future processors.
Clearly, better forecasts will require many things, but none is bigger than the investment needed in capable, innovative scientists. Emphasis, for now, should therefore be placed on growing our intellectual capacity to realize smarter uses of affordable, available computing resources. Engaging computing scientists in the fascinating world of weather and climate prediction would be a valuable first step.
© 2008-2021. All rights reserved. Any copying, redistribution or retransmission of any of the contents of this service without the expressed written permission of the American Geosciences Institute is expressly prohibited. Click here for all copyright requests.